
A Tour of Local AI in Early 2024
What is the state of local generative AI? After getting an NVIDIA RTX 4090 for local AI, I wanted to review this for myself. And enough people have asked, that I thought I’d write up my thoughts.
Long story short, the latest capabilities are unbelievable. They are absolutely good enough to make game changing new features and products possible.
And yet, I’m not worried about “AI taking our jobs”. A common theme across all the types of models is that, despite the impressive capabilities, these models’ output is still not good enough.
Human’s will be in the loop to guide prompts, gather and clean data, review the output. The output simply isn’t good enough without significant human engineering and artistic effort.
I’ve broken this post up into sections devoted to each type of model:
- Text Generation: interactive chat, text completion
- Coding Assistant: advanced code completion, program creation
- Image Generation: creating images based on text prompts
- Multimodal AI: combining scene understanding with text generation
- Music Generation: creating music based on prompts & audio samples
- Speech-to-Text: transcribing audio into text
- Text-to-Speech: turning text into natural sounding audio/speech
I’ll try to keep each section brief. But and I’ve kept the longest for last.
Text-to-Speech was the main reason I embarked on this adventure. And, wow it paid off big time.
Text Generation
2023 was the year of LLM’s. Between ChatGPT’s meteoric rise and the release of open source models, AI suddenly became accessible to everyone. But, where do we stand in 2024 for local options?
The best thing in 2024 is that there are mature options to easily run models locally. I’ve used LLamafile and Ollama. But for a graphical experience, I’d recommend LM Studio.
These apps are basically point and click. That means for anyone with an M-series Mac (ie. M1/M2/M3), you can use LLM’s today with no technical experience necessary.
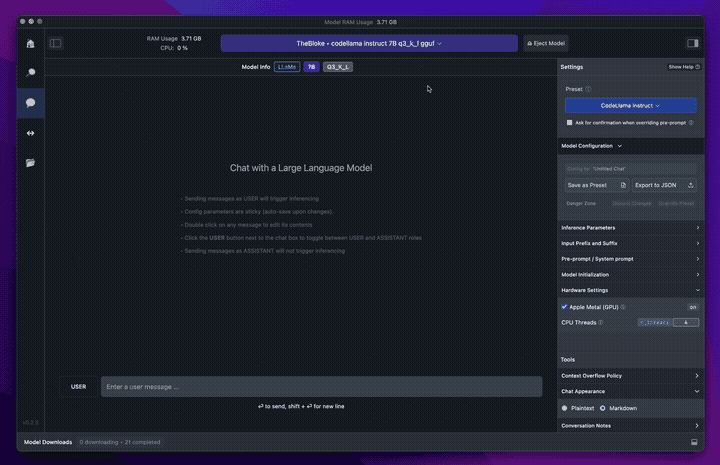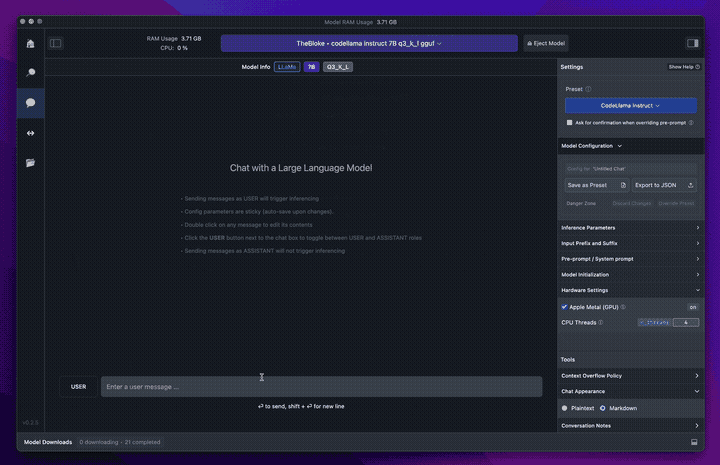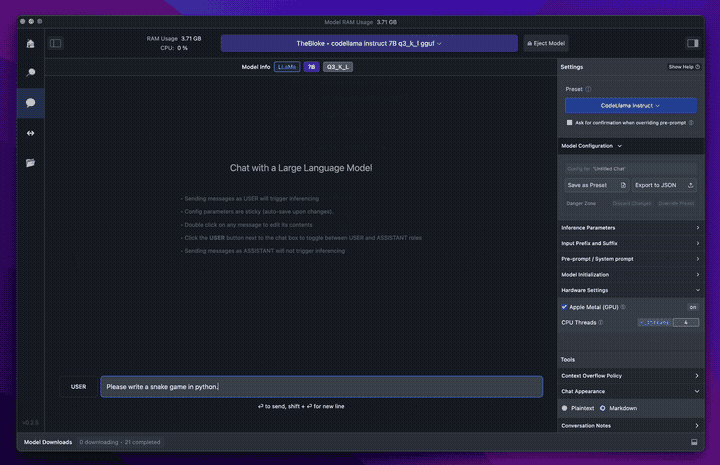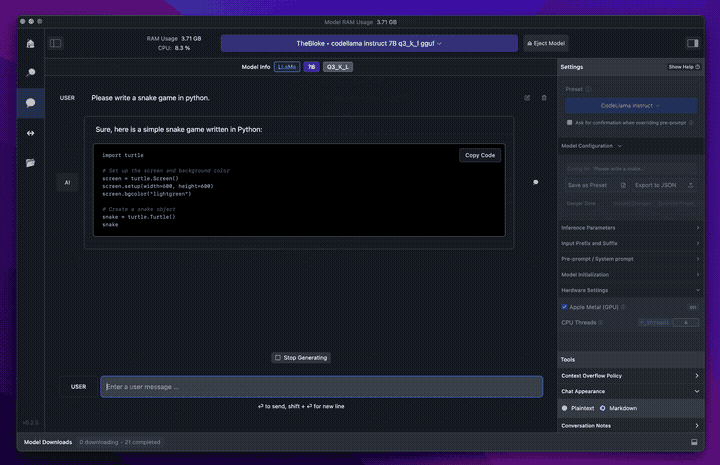
Not only is it easier than ever to run models locally. But, there’s also a ton of truly open source models now and there’s even more that have weights published on HuggingFace under less-open, but still possibly runnable licenses.
This variety is great, because if you find a model that isn’t good at what you’re trying to do, you can search and find one that is. It’s like an online library of experts that are one click away.
And finally, another more recent feature that I’ve found extremely useful is “constrained grammar-based sampling”, meaning you can strictly control how the LLM responds. For example, you can limit the response to exactly yes or no with no additional confabulation or explanations.
For programmers this is great, because you can force structured output (ex. with JSON) and easily parse it.
So although the locally runnable models are still not as good as what is commercially available, they’re excellent and super useful for a ton of things.
Some things I’ve enjoyed doing with AI include:
- Text summarization: Summarize this news article
- Classification: Is the above text talking about XYZ?
- Recipes: Write a recipe for vegan enchiladas
- Writing short stories: Write a story about a ninja and pirate that go on an adventure together
- Brainstorming: What are 10 creative date ideas that you can do at home
But the ideas are endless! An interesting area I’d like to explore is using LLM’s to assist in writing prompts for image generators. I’d also like to test out automatic email replies for some common questions I get through email.
Coding Assistant
GitHub’s CoPilot and similar products have gotten fairly wide adoption among developers. But what is the state of open source coding assistants?
I was definitely a skeptic. I tend to avoid the complicated setups that most dev’s use. However, I was surprised to find myself really enjoying Tabby.

M-series Mac’s can comfortably run the 1B to 7B models, including StarCoder, CodeLlama, and DeepseekCoder. Though I found only the 1B and 3B models to have acceptable speed for me.
However, it really gets interesting with the larger graphics card. My 4090 can run up to 70B models (quantized to 5-bits with minimal loss) and provide much better results. Though I still only run the 7B model due to the speed.
One downside is that currently, the models all have restrictions that make them not fully open source. They’re still usable for my personal, private use cases. But I hope that this will change soon.
All told, the open source coding models are not revolutionary in my experience. But they are pretty good for repetitive and simple cases.
And for me, Tabby is solidly a useful tool. I expect I’ll continue using it!
Image Generation
This has been by far the most fun of the models listed here!
DALL·E, Bing Image Creator, Midjourney and other commercial image generators have been producing amazing results for years now.
And ever since Stable Diffusion released their model in 2022, there have been viable open source options. But what’s the quality like now in 2024?
Well, Stable Diffusion XL is out. It runs fast on my 4090. And the results are amazing (at least to me). I generated the top image of this post! And here’s some more samples generations I’ve done:

I’ve been running SDXL using InvokeAI. This is a web-based UI that requires a decent amount of technical knowledge to run.
But, there are a variety of very advanced UI’s that are easy to install and run. For example DiffusionBee works great on M-series Mac’s (M1/M2/M3).
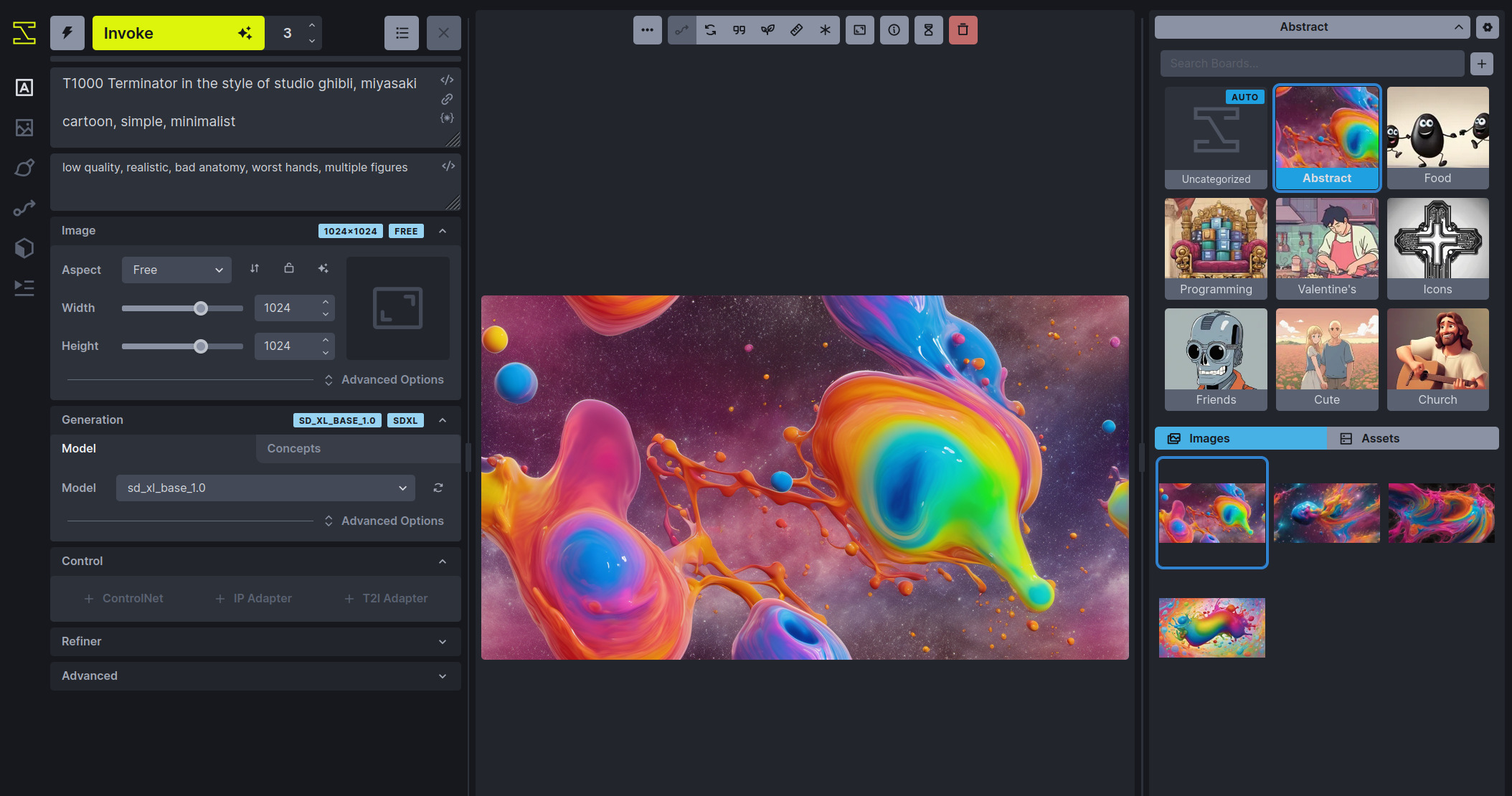
Right now, the output I’ve gotten fluctuates wildly. You never know what you are going to get. And it feels like pulling the lever on a slot machine. Super addictive.
That’s exciting and fun. But also takes a long time and a lot of tweaks to get what you want. So, I’m starting to explore the advanced tools like the node-based workflow and other tools which gives even more control over the resulting image.
I’ve also tried out a couple fine-tuned models, such as one optimized to making logos. And, I tried some “ControlNet” features like fixing mangled hands and faces. But, I know there’s a lot more to learn.
Multimodal AI
There’s a lot of pictures out there. And this is the latest frontier of AI model development. It’s one of the headline features of GPT-4. And it’s an huge part of the Gemini demo videos as well.
So what capabilities are there in open source land? Currently, LLaVa is the go-to model. And it’s usable in my experience.

I didn’t spend much time here, because it’s not that interesting to me. The main application I’ve found interesting is indexing your personal photos and doing search.
But I also have heard rumblings of this being he key for AI in robotics and for AI independently navigating the web effectively.
But generally, it works and is usable. You can run them through most of the LLM apps. Not much else to say.
Music Generation
Until last August, AI generated music has been mainly the realm of research or forthcoming commercial products. But Facebook’s AudioCraft has opened up a new open source option.
Like with an image generator or LLM, you prompt it with a phrase. And it will generate a snippet of music. You set the length and a number of other parameters.
The results are neat! The quality is still so-so. But it can generate some useful snippets for loops, intro, or outro music. Here’s an example:
Speech-to-Text

I didn’t play around in this area too much, because Whisper.cpp is so good already and runs on very meager hardware.
So there wasn’t much point testing other STT systems on my new, more powerful graphics card.
The GUI app’s still leave something to be desired. The best I’ve seen so far is WhisperScript for Mac.
So for now, this is still limited to more technical users. But, I’d expect desktop & smartphone apps to come soon. Or, Whisper.cpp and similar programs will be integrated into other audio-based apps like podcast apps, audio editors/DAW’s, and more.

Text-to-Speech
![]()
This was the main reason I bought the graphics card.
For context, I listen to a lot of audio during the day. Like, easily 9 hours of audio per day in the background while I’m working, walking, and doing other things. I realize that’s unusual, but I assure you I can absorb a lot of it and still get work done.
Podcasts and YouTube are a lot of that. But for the past few months, about 2 hours of it has been web articles through text-to-speech using Piper.
As you can hear, the quality is listenable. There’s still a bit of robotic-ness, but I’ve been able to listen to a lot of it without getting tired or not being able to follow.
However, there is enough robotic-ness that I have been eager to try out the state-of-the-art.
The quality of commercial offerings is amazing. Oftentimes indistinguishable from professional narration from my untrained ear. But, they charge truly astounding rates. For example, ElevenLabs has about $8 to $11 per hour depending on your plan.1 At my consumption, it would cost nearly $500 per month.
So if the more advanced open source models can get even close to commercial quality level, it was easy to justify the graphics card. It pays for itself after only a few months. And, wow did it pay off!
![]()
The first project I tried was Coqui TTS. And, the output of the XTTS model is great. This model is non-commercial, among other restrictions. However, that’s fine for my use case.
I also tried Tortoise TTS, which has a fully open source license (including the weights). It is a big step up from Piper. However, it is noticably worse than Coqui’s XTTS (but still a lot better than Piper).

But either way, this was revolutionary for me. I have been listening to several hours of Coqui TTS output per day. And, it’s awesome. It has human-like tone and prosody. It’s able to pronounce a surprising variety of highly specific words.
For the downsides: it struggles often with acronyms and abbreviations. And, it’s terrible at reading code. It also occasionally hallucinates a word or two. And may once in every hour of audio, it injects about 3-5 seconds of totally hallucinated mumbling and confabulation. But it picks up with the text right after.
But all told, I’m thrilled. I got exactly what I wanted, basically unlimited amount of locally generated, podcast quality audio.
Like with Speech-to-Text, though. This capability (at least locally) is still locked behind a technical barrier.
To use these systems, you need to be comfortable with installing dependencies, debugging Python code, and other technical weirdness.
Additionally, the models I tried are all NVIDIA specific, which means it’s not accessible to most people. So it’ll be a while before these models are ported to more common hardware and people start making GUI apps.
Conclusion
Getting a 4090 has opened up an amazing universe of capabilities for me. The quality of open source models (or semi-open, non-commercial licensed) and tools are great!
Some still require technical knowledge to run. But I predict that most of this will come to non-technical users fairly soon.
Advances on inference performance are coming every day. And competition among hardware manufacturers will put a lot of pressure on delivering on-device inference capabilities, especially since Apple is so far ahead in this area.
But just for my use, I’ve been having a blast and getting tons of value out of AI!
- ElevenLabs’ pricing at time of writing (after promotional periods) is $22 for ~2 hours ($11/hr), $99 for ~10 hours ($10/hr), $330 for ~40 hours ($8/hr), or the dreaded Let’s Talk.