Naïveté in Early Character Encoding
Previously, I’ve written on interesting English words like éxpose, adiós, and naïveté, and then the solution to typing these.
And now it’s time for some history! Why does this problem even exist?
ASCII History & How Character Encodings Work§
Computers need a way of mapping binary numbers to character symbols so that
they can draw them on screen. For example, they see the number 33 (ie.
00100001 in binary) and need to show the exclamation point character!
However due to early computers’ limited processing power, programmers wanted to use the smallest space possible. That meant they could only support drawing 128 different characters.
That lead to the ASCII standard shown below:
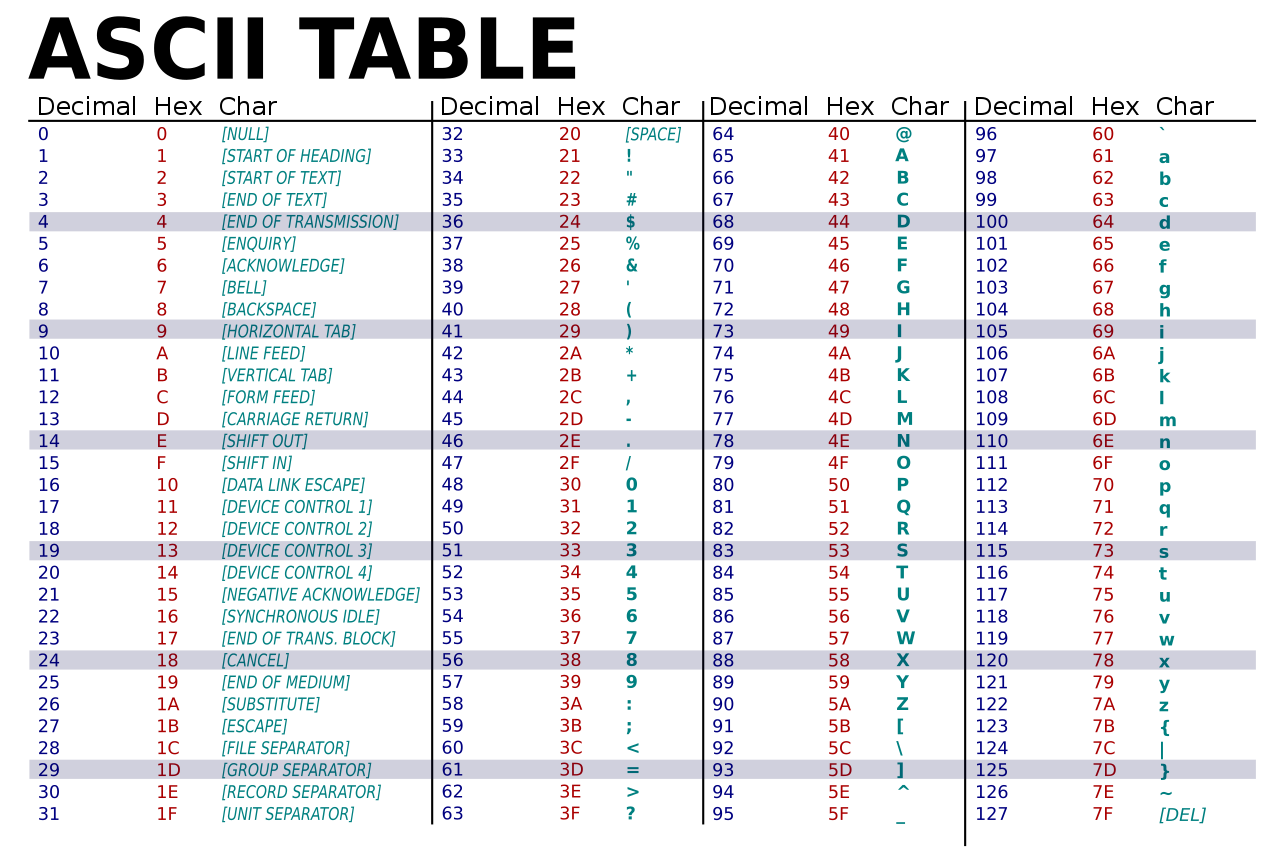
This table obviously cannot represent the fullness of all human languages. So there have been many different character encodings proposed since then.
The most prominent now is utf8 via the Unicode standard.
Unfortunately, some programmers don’t appreciate how many interesting words english has borrowed from other languages. So, they don’t test a variety of text, making their systems break or show Mojibake.
So next time you are testing a system, try to find resources to improve your tests, such as the Big List of Naughty Strings or fuzz testing tools.
Conclusion§
Thanks for entertaining my dive into the English language and how character encodings let us express it fully. If you liked this series, let me know!